
上篇貼了我第一次解這題時的硬幹版本。
那個版本可以 AC,代表方向其實沒有錯。
但能過,不代表這就是一個夠直接、夠乾淨的解法。
原本的解法:
public String longestCommonPrefix(String[] strs) {
String minimumString = "";
int minimum = 300;
for(int i = 0;i<strs.length;i++){
if(strs[i].length() < minimum){
minimum = strs[i].length();
minimumString = strs[i];
}
}
if(minimumString.equals("")){
return "";
}
for(int i = 0;i<strs.length;i++){
String target = strs[i];
int lastIndex = minimumString.length() - 1;
while(!target.startsWith(minimumString)){
if(minimumString.equals("")){
return "";
}
minimumString = minimumString.substring(0,lastIndex);
lastIndex--;
}
}
return minimumString;
}
核心思路其實很直觀:
最長共同前綴,不可能比最短字串還長。
所以先掃一輪,找出陣列裡最短的字串,拿它當作候選前綴。
接著逐一檢查其他字串,如果某個字串不是以這個前綴開頭,就把前綴砍短一點,再繼續檢查。
一直砍,砍到全部都符合,或者砍到空字串為止。
但是這樣解在過程中有幾個地方浪費效率了。
問題一:startsWith 在幹嘛?
直觀上來說,「檢查字串是否以否個前綴開頭」時,使用 startsWith 是很直接也很合理的作法。
但問題是,startsWith 的底層是逐字比較前綴,單次使用的成本是 O(m),m是前綴長度。
在這題上我們是否需要每次都逐字比較前綴? 問題出在這裡。
因為其實我們不需要逐字比較,也能找出共同最長前綴。
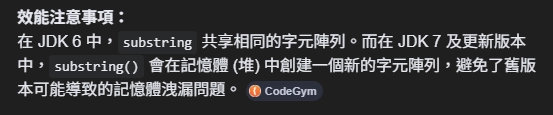
問題二:substring 浪費記憶體
透過 substring 來砍字串,能行。
但是每次使用 substring ,都會建立一個新的字串,同樣的。
我們其實不需要重複地做這件事情,只需要找對地方砍一刀就好。
問題三:不需要”找出最短字串”
int minimum = 300;
for(int i = 0;i<strs.length;i++){
if(strs[i].length() < minimum){
minimum = strs[i].length();
minimumString = strs[i];
}
}
if(minimumString.equals("")){
return "";
}原本的核心思路”最長共同前綴,不可能比最短字串還長。” 其實是有道理的。
但是問題是:要找出最常共同前綴,我們不需要最短字串來判斷。
舉個例子
["flower", "flow", "flight"]如果我們改成逐字檢查
- index 0:
f、f、f,一致 - index 1:
l、l、l,一致 - index 2:
o、o、i,不一致
答案自然就是 "fl"。
整個過程完全沒有最短字串的參與,如果效能為解題考量,那麼找出最短字串這個步驟就需要捨棄掉。
由此可以看出一個解法:
逐字元比對
public String longestCommonPrefix(String[] strs) {
if (strs == null || strs.length == 0) {
return "";
}
for (int i = 0; i < strs[0].length(); i++) {
char c = strs[0].charAt(i);
for (int j = 1; j < strs.length; j++) {
if (i == strs[j].length() || strs[j].charAt(i) != c) {
return strs[0].substring(0, i);
}
}
}
return strs[0];
}
先拿第一個字串當基準。
看第 0 個字元,其他字串在第 0 個位置是不是都一樣。
如果都一樣,就繼續看第 1 個字元。
只要遇到某個字串長度不夠,或者某個位置的字元不同,就直接回傳目前為止的前綴。
例如:
["flower", "flow", "flight"]流程會是:
- 看 index 0:
f,全部一致 - 看 index 1:
l,全部一致 - 看 index 2:
o、o、i,不一致
所以答案就是 "fl"。
補充:複雜度怎麼看?
這個版本的時間複雜度可以看成:O(n * m)
n是字串數量m是實際檢查到的前綴長度
最差情況下,程式會把每個字串的每個對應位置都看過一次。
空間複雜度則會接近:O(1)
因為如果不把最後回傳的字串算進額外空間,中間基本上沒有多開什麼資料結構。
至於原本的暴力版本,雖然最後也能 AC,
但因為裡面反覆做了 startsWith 與 substring,會多出不少重複比對與額外字串建立成本。
發佈留言